


🪵🪵🪵 Raft is not yet good enough. This project intends to improve raft as the next-generation consensus protocol for distributed data storage systems (SQL, NoSQL, KV, Streaming, Graph ... or maybe something more exotic).
Currently, openraft is the consensus engine of meta-service cluster in databend.
-
Get started: The guide is the best place to get started, followed by the docs for more in-depth details.
-
Openraft FAQ explains some common questions.
-
🙌 Questions? Join the Discord channel or start a discussion.
-
Openraft is derived from async-raft with several bugs fixed: Fixed bugs.
Status
-
Openraft API is not stable yet. Before
1.0.0, an upgrade may contain incompatible changes. Check our change-log. A commit message starts with a keyword to indicate the modification type of the commit:DataChange:on-disk data types changes, which may require manual upgrade.Change:if it introduces incompatible changes.Feature:if it introduces compatible non-breaking new features.Fix:if it just fixes a bug.
-
Branch main has been under active development.
The main branch is for the 0.8 release.
- The features are almost complete for building an application.
- The performance isn't yet fully optimized. Currently, it's about 48,000 writes per second with a single writer.
- Unit test coverage is 91%.
- The chaos test is not yet done.
-
Branch release-0.8: Latest published: v0.8.1 | Change log v0.8.1 | ⬆️ 0.7 to 0.8 upgrade guide |
-
Branch release-0.7: Latest published: v0.7.4 | Change log v0.7.4 | ⬆️ 0.6 to 0.7 upgrade guide |
release-0.7Won't accept new features but only bug fixes. -
Branch release-0.6: Latest published: v0.6.8 | Change log v0.6 |
release-0.6won't accept new features but only bug fixes.
Roadmap
-
2022-10-31 Extended joint membership
-
2023-02-14 Minimize confliction rate when electing; See: Openraft Vote design; Or use standard raft mode with feature flag
single-term-leader. -
Reduce the complexity of vote and pre-vote: get rid of pre-vote RPC;
-
Support flexible quorum, e.g.:Hierarchical Quorums
-
Consider introducing read-quorum and write-quorum, improve efficiency with a cluster with an even number of nodes.
-
Goal performance is 1,000,000 put/sec.
Bench history:
- 2022 Jul 01: 41,000 put/sec; 23,255 ns/op;
- 2022 Jul 07: 43,000 put/sec; 23,218 ns/op; Use
Progressto track replication. - 2022 Jul 09: 45,000 put/sec; 21,784 ns/op; Batch purge applied log
- 2023 Feb 28: 48,000 put/sec; 20,558 ns/op;
Run the benchmark:
make bench_cluster_of_3Benchmark setting:
- No network.
- In memory store.
- A cluster of 3 nodes on one server.
- Single client.
Features
-
It is fully reactive and embraces the async ecosystem. It is driven by actual Raft events taking place in the system as opposed to being driven by a
tickoperation. Batching of messages during replication is still used whenever possible for maximum throughput. -
Storage and network integration is well defined via two traits
RaftStorage&RaftNetwork. This provides applications maximum flexibility in being able to choose their storage and networking mediums. -
All interaction with the Raft node is well defined via a single public
Rafttype, which is used to spawn the Raft async task, and to interact with that task. The API for this system is clear and concise. -
Log replication is fully pipelined and batched for optimal performance. Log replication also uses a congestion control mechanism to help keep nodes up-to-date as efficiently as possible.
-
It fully supports dynamic cluster membership changes with joint config. The buggy single-step membership change algo is not considered. See the
dynamic membershipchapter in the guide. -
Details on initial cluster formation, and how to effectively do so from an application's perspective, are discussed in the cluster formation chapter in the guide.
-
Automatic log compaction with snapshots, as well as snapshot streaming from the leader node to follower nodes is fully supported and configurable.
-
The entire code base is instrumented with tracing. This can be used for standard logging, or for distributed tracing, and the verbosity can be statically configured at compile time to completely remove all instrumentation below the configured level.
Who use it
Contributing
Check out the CONTRIBUTING.md guide for more details on getting started with contributing to this project.
License
Openraft is licensed under the terms of the MIT License or the Apache License 2.0, at your choosing.
Getting Started
In this chapter we are going to build a key-value store cluster with openraft.
examples/raft-kv-memstore is the complete example application including the server, the client and a demo cluster.
examples/raft-kv-rocksdb is the complete example application including the server, the client and a demo cluster using rocksdb for persistent storage.
Raft is a distributed consensus protocol designed to manage a replicated log containing state machine commands from clients.
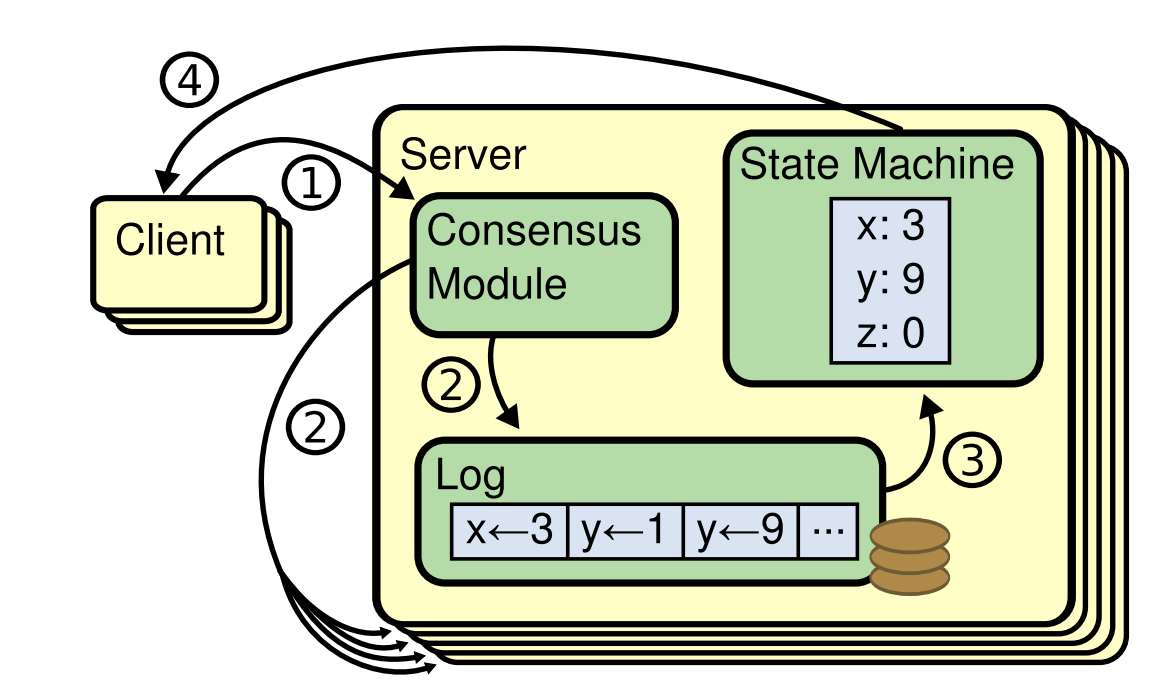
Raft includes two major parts:
- How to replicate logs consistently among nodes,
- and how to consume the logs, which is defined mainly in state machine.
To implement your own raft based application with openraft is quite easy, which includes:
- Define client request and response;
- Implement a storage to let raft store its state;
- Implement a network layer for the raft to transmit messages.
1. Define client request and response
A request is some data that modifies the raft state machine. A response is some data that the raft state machine returns to the client.
Request and response can be any types that impl AppData and AppDataResponse,
e.g.:
#![allow(unused)] fn main() { #[derive(Clone, Debug, Serialize, Deserialize)] pub struct ExampleRequest {/* fields */} impl AppData for ExampleRequest {} #[derive(Clone, Debug, Serialize, Deserialize)] pub struct ExampleResponse(Result<Option<String>, ClientError>); impl AppDataResponse for ExampleResponse {} }
These two types are totally application-specific and are mainly related to the
state machine implementation in RaftStorage.
2. Implement RaftStorage
The trait RaftStorage defines the way that data is stored and consumed.
It could be a wrapper of some local KV store such RocksDB
or a wrapper of a remote SQL DB.
RaftStorage defines four sets of APIs an application needs to implement:
-
Read/write raft state, e.g., term or vote.
#![allow(unused)] fn main() { fn save_vote(vote:&Vote) fn read_vote() -> Result<Option<Vote>> } -
Read/write logs.
#![allow(unused)] fn main() { fn get_log_state() -> Result<LogState> fn try_get_log_entries(range) -> Result<Vec<Entry>> fn append_to_log(entries) fn delete_conflict_logs_since(since:LogId) fn purge_logs_upto(upto:LogId) } -
Apply log entry to the state machine.
#![allow(unused)] fn main() { fn last_applied_state() -> Result<(Option<LogId>, Option<EffectiveMembership>)> fn apply_to_state_machine(entries) -> Result<Vec<AppResponse>> } -
Building and installing a snapshot.
#![allow(unused)] fn main() { fn build_snapshot() -> Result<Snapshot> fn get_current_snapshot() -> Result<Option<Snapshot>> fn begin_receiving_snapshot() -> Result<Box<SnapshotData>> fn install_snapshot(meta, snapshot) }
The APIs have been made quite obvious, and there is a good example
ExampleStore,
which is a pure-in-memory implementation that shows what should be done when a
method is called.
How do I impl RaftStorage correctly?
There is a Test suite for RaftStorage, if an implementation passes the test, openraft will work happily with it.
To test your implementation with this suite, just do this:
#![allow(unused)] fn main() { #[test] pub fn test_mem_store() -> anyhow::Result<()> { openraft::testing::Suite::test_all(MemStore::new) } }
There is a second example in Test suite for RaftStorage that showcases building a rocksdb backed store.
Race condition about RaftStorage
In our design, there is at most one thread at a time writing data to it. But there may be several threads reading from it concurrently, e.g., more than one replication task reading log entries from the store.
An implementation has to guarantee data durability.
The caller always assumes a completed write is persistent. The raft correctness highly depends on a reliable store.
3. impl RaftNetwork
Raft nodes need to communicate with each other to achieve consensus about the
logs.
The trait RaftNetwork defines the data transmission requirements.
An implementation of RaftNetwork can be considered as a wrapper that invokes the
corresponding methods of a remote Raft.
#![allow(unused)] fn main() { pub trait RaftNetwork<D>: Send + Sync + 'static where D: AppData { async fn send_append_entries(&self, target: NodeId, node:Option<Node>, rpc: AppendEntriesRequest<D>) -> Result<AppendEntriesResponse>; async fn send_install_snapshot( &self, target: NodeId, node:Option<Node>, rpc: InstallSnapshotRequest,) -> Result<InstallSnapshotResponse>; async fn send_vote(&self, target: NodeId, node:Option<Node>, rpc: VoteRequest) -> Result<VoteResponse>; } }
ExampleNetwork shows how to forward messages to other raft nodes.
And there should be a server endpoint for each of these RPCs.
When the server receives a raft RPC, it just passes it to its raft instance and replies with what returned:
raft-server-endpoint.
As a real-world impl, you may want to use Tonic gRPC. databend-meta would be an excellent real-world example.
Find the address of the target node.
An implementation of RaftNetwork need to connect to the remote raft peer,
through TCP etc.
You have two ways to find the address of a remote peer:
-
Managing the mapping from node-id to address by yourself.
-
openraftallows you to store the additional info in its internal Membership, which is automatically replicated as regular logs.To use this feature, you need to pass a
Nodeinstance, which contains address and other info, toRaft::add_learner():-
Raft::add_learner(node_id, None, ...)tellsopenraftto store only node-id inMembership. The membership data then would be like:"membership": { "learners": [], "configs": [ [ 1, 2, 3 ] ], "nodes": {} } -
Raft::add_learner(node_id, Some(Node::new("127.0.0.1")), ...)tellsopenraftto store node-id, and its address inMembershiptoo:"membership": { "learners": [], "configs": [ [ 1, 2, 3 ] ], "nodes": { "1": { "addr": "127.0.0.1:21001", "data": {} }, "2": { "addr": "127.0.0.1:21002", "data": {} }, "3": { "addr": "127.0.0.1:21003", "data": {} } } }
-
4. Put everything together
Finally, we put these parts together and boot up a raft node main.rs :
#[tokio::main] async fn main() { #[actix_web::main] async fn main() -> std::io::Result<()> { // Setup the logger env_logger::init_from_env(Env::default().default_filter_or("info")); // Parse the parameters passed by arguments. let options = Opt::parse(); let node_id = options.id; // Create a configuration for the raft instance. let config = Arc::new(Config::default().validate().unwrap()); // Create a instance of where the Raft data will be stored. let store = Arc::new(ExampleStore::default()); // Create the network layer that will connect and communicate the raft instances and // will be used in conjunction with the store created above. let network = Arc::new(ExampleNetwork {}); // Create a local raft instance. let raft = Raft::new(node_id, config.clone(), network, store.clone()); // Create an application that will store all the instances created above, this will // be later used on the actix-web services. let app = Data::new(ExampleApp { id: options.id, raft, store, config, }); // Start the actix-web server. HttpServer::new(move || { App::new() .wrap(Logger::default()) .wrap(Logger::new("%a %{User-Agent}i")) .wrap(middleware::Compress::default()) .app_data(app.clone()) // raft internal RPC .service(raft::append) .service(raft::snapshot) .service(raft::vote) // admin API .service(management::init) .service(management::add_learner) .service(management::change_membership) .service(management::metrics) .service(management::list_nodes) // application API .service(api::write) .service(api::read) }) .bind(options.http_addr)? .run() .await } }
5. Run the cluster
To set up a demo raft cluster includes:
- Bring up three uninitialized raft nodes;
- Initialize a single-node cluster;
- Add more raft nodes into it;
- Update the membership config.
examples/raft-kv-memstore describes these steps in detail.
And two test scripts for setting up a cluster are provided:
-
test-cluster.sh is a minimized bash script using curl to communicate with the raft cluster, to show what messages are sent and received in plain HTTP.
-
test_cluster.rs Use ExampleClient to set up a cluster, write data, and then read it.
FAQ
-
Q: 🤔 Why is heartbeat an append-entries RPC with a blank log in openraft, while standard Raft uses empty append-entries?
Chapter Heartbeat explains the benefit of the heartbeat-log design.
-
Q: 🤔 Why is log id
(term, node_id, log_index), while standard Raft uses just(term, log_index)?TODO
Cluster Controls
A raft cluster may be controlled in various ways using the API methods of the Raft type.
This allows the application to influence the raft behavior.
There are several concepts related to cluster control:
-
Voter: a raft node that is responsible to vote, elect itself for leadership(Candidate), become Leader or Follower
-
Candidate: a node tries to elect itself as the Leader.
-
Leader: the only node in a cluster that deals with application request.
-
Follower: a node that believes there is a legal leader and just receives replicated logs.
-
Learner: a node that is not allow to vote but only receives logs.
Voter state transition:
vote granted by a quorum
.--> Candidate ----------------------> Leader
heartbeat | | |
timeout | | seen a higher Leader | seen a higher Leader
| v |
'----Follower <--------------------------'
Cluster Formation
A Raft node enters Learner state when it is created by Raft::new().
To form a cluster, application must call Raft::initialize(membership).
Raft::initialize()
This method will:
-
Append one membership log at index 0, the log id has to be
(leader_id=(0,0), index=0). The membership will take effect at once. -
Enter Candidate state and start vote to become leader.
-
The leader will commit a blank log to commit all preceding logs.
Errors and failures
-
Calling this method on an already initialized node just returns an error and is safe, i.e.
last_log_idon this node is not None, orvoteon this node is not(0,0). -
Calling this method on more than one node at the same time:
-
with the same
membership, it is safe. Because voting protocol guarantees consistency. -
with different
membershipit is ILLEGAL and will result in an undefined state, AKA the split-brain state.
-
Conditions for initialization
The conditions for a legal initialization is as the above because:
The first membership log with log id (vote, index=0) will be appended to initialize a node, without consensus.
This has not to break the commit condition:
-
Log id
(vote, index=0)must not be greater than any committed log id. ifvoteis not the smallest value, i.e.(term=0, node_id=0), it has chance to be greater than some committed log id. This is why the first log has to be the smallest:((term=0, node_id=0), 0). -
And a node should not append a log that is smaller than its
vote. Otherwise, it is actually changing the history other nodes has seen. This has chance to (but not certainly will) break the consensus, depending on the protocol. E.g. if the cluster has been running a fast-paxos like protocol, appending a smaller log thanvoteis illegal. By not allowing to append a smaller log thanvote, it will always be safe.
From these two reason, it is only allowed to append the first log if:
vote==(0,0). And this is why the initial value of vote has to be (0,0).
Dynamic Membership
Unlike the original raft, openraft treats all membership as a joint membership. A uniform config is just a special case of joint: the joint of only one config.
Openraft offers these mechanisms for controlling member node lifecycle:
Membership API
Raft::add_learner(node_id, node, blocking)
This method will add a learner to the cluster, and immediately begin syncing logs from the leader.
- A Learner won't vote for leadership.
Raft::change_membership(members, allow_lagging, turn_to_learner)
This method initiates a membership change and returns when the effective
membership becomes members and is committed.
If there are nodes in the given membership that is not a Learner, this method will fail.
Thus the application should always call Raft::add_learner() first.
Once the new membership is committed, a Voter not in the new config is removed if turn_to_learner=false,
and it is reverted to a Learner if turn_to_learner=true.
Example of turn_to_learner
Given the original membership to be {"members":{1,2,3}, "learners":{}},
call change_membership with members={3,4,5}, then:
- If
turn_to_learner=true, the new membership is{"members":{3,4,5}, "learners":{1,2}}. - If
turn_to_learner=false, the new membership is{"members":{3,4,5}, "learners":{}}.
Add a new node as a voter
To add a new node as a voter:
- First, add it as a
learner(non-voter) withRaft::add_learner(). In this step, the leader sets up replication to the new node, but it can not vote yet. - Then turn it into a
voterwithRaft::change_membership().
#![allow(unused)] fn main() { let client = ExampleClient::new(1, get_addr(1)?); client.add_learner((2, get_addr(2)?)).await?; client.add_learner((3, get_addr(3)?)).await?; client.change_membership(&btreeset! {1,2,3}).await?; }
A complete snippet of adding voters can be found in the example app.
Remove a voter node
-
Call
Raft::change_membership()on the leader to initiate a two-phase membership config change, e.g., the leader will propose two config logs: joint config log:[{1, 2, 3}, {3, 4, 5}]and then the uniform config log:{3, 4, 5}. -
As soon as the leader commits the second config log, the node to remove can be terminated safely.
Note that An application does not have to wait for the config log to be replicated to the node to remove. Because a distributed consensus protocol tolerates a minority member crash.
To read more about openraft's extended membership algorithm.
Node life cycle
-
When a node is added with
Raft::add_learner(), it starts to receive log replication from the leader at once, i.e., becomes aLearner. -
A learner becomes a
Voter, whenRaft::change_membership()adds it aVoter. AVoterwill then becomeCandidateorLeader. -
When a node, no matter a
LearnerorVoter, is removed from membership, the leader stops replicating to it at once, i.e., when the new membership that does not contain the node is seen(no need to commit).The removed node won't receive any log replication or heartbeat from the leader. It will enter
Candidatebecause it does not know it is removed.
Remove a node from membership config
When membership changes, e.g., from a joint config [(1,2,3), (3,4,5)] to uniform config [3,4,5](assuming the leader is 3), the leader
stops replication to 1,2 when the uniform config [3,4,5] is seen(no need to be committed).
It is correct because:
-
If the leader(
3) finally committed[3,4,5], it will eventually stop replication to1,2. -
If the leader(
3) crashes before committing[3,4,5]:- And a new leader sees the membership config log
[3,4,5], it will continue to commit it and finally stop replication to1,2. - Or a new leader does not see membership config log
[3,4,5], it will re-establish replication to1,2.
- And a new leader sees the membership config log
In any case, stopping replication at once is OK.
One of the considerations is:
The nodes, e.g., 1,2 do not know they have been removed from the cluster:
-
Removed node will enter the candidate state and keeps increasing its term and electing itself. This won't affect the working cluster:
-
The nodes in the working cluster have greater logs; thus, the election will never succeed.
-
The leader won't try to communicate with the removed nodes thus it won't see their higher
term.
-
-
Removed nodes should be shut down finally. No matter whether the leader replicates the membership without these removed nodes to them, there should always be an external process that shuts them down. Because there is no guarantee that a removed node can receive the membership log in a finite time.
Metrics
Raft exports metrics on its internal state via Raft::metrics() -> watch::Receiver<RaftMetrics>.
RaftMetrics contains useful information such as:
- role of this raft node,
- the current leader,
- last, committed, applied log.
- replication state, if this node is a Leader,
- snapshot state,
Metrics can be used as a trigger of application events, as a monitoring data source, etc.
Metrics is not a stream thus it only guarantees to provide the latest state but
not every change of the state.
Because internally, watch::channel() only stores one state.
Feature flags
By default openraft enables no features.
-
bt: attaches backtrace to generated errors. -
serde: derivesserde::Serialize, serde::Deserializefor type that are used in storage and network, such asVoteorAppendEntriesRequest. -
single-term-leader: allows only one leader to be elected in eachterm. This is the standard raft policy, which increases election confliction rate but reduceLogId((term, node_id, index)to(term, index)) size. Read more about how it is implemented invote -
compat-07: provides additional data types to build v0.7 compatible RaftStorage.compat-07 = ["compat", "single-term-leader", "serde", "dep:or07", "compat-07-testing"] compat-07-testing = ["dep:tempdir", "anyhow", "dep:serde_json"]
Internal
In this chapter we explains how openraft internally works.
Architecture
.~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~.
! User !
! o !
! | !
! | !
! | "client_write(impl AppData) -> impl AppDataResponse"
! | "is_leader()" !
! | "add_learner()" !
! | "change_membership()"!
! v !
! Raft ! .-------------> Raft -----.
'~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~' | |
| | |
| enum RaftMes | |
| | |
.~~~~~~~|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~. | |
! v ! | RPC: v
.----------------o RaftCore ! | "vote()" RaftCore
| ! o ! | "append_entries()"
| ! .--+--------. ! | "install_snapshot()"
| ! v v ! |
| ! ReplicationState ReplicationState ! |
| '~~|~~~~~~~~~~~~~~~~|~~~~~~~~~~~~~~~~~~~' |
| | | |
| | | |
| .~~~~~~~~~~|~~~~~~~~~~. .~~|~~~~~~~~~~~~~~~~~~~. |
| ! v ! ! v ! |
| ! ReplicationStream ! ! ReplicationStream ! |
| ! o ! ! o o ! |
| '~|~~~~~~~~~~~~~~~~~~~' ! | | ! |
| | ! | v ! |
| | ! | Arc<RaftNetwork> -----'
| | '~~|~~~~~~~~~~~~~~~~~~~'
| | |
| `-------------------------+
| | "get_log()"
| | "..."
| v
`----------------------> Arc<RaftStorage>
"append_log()" o
"..." |
v
local-disk
----------------------------------------------- -----------------------------------------------
Node 1 Node 2
Legends:
.~~~~~~~~~~~~~~.
! "tokio task" !
'~~~~~~~~~~~~~~'
o--> function call
---> async communication: through channel or RPC
Threads(tasks)
There are several threads, AKA tokio-tasks in this raft impl:
-
RaftCore: all logs and state machine operations are done in this thread. Thus there is no race condition
- All raft state runs in this task, such as LeaderState, CandidateState etc.
- All write to store is done in this task, i.e., write to store is serialized.
Lifecycle:
- RaftCore thread is spawnd when a raft node is created and keeps running until the raft node is dropped.
-
Replication tasks:
There is exactly one replication task spawned for every replication target, i.e., a follower or learner.
A replication task replicates logs or snapshot to its target. A replication thread do not write logs or state machine, but only read from it.
Lifecycle:
-
A replication task is spawned when RaftCore enters
LeaderState, or a leader target is added by user. -
A replication task is dropped when a follower of learner is removed by change-membership or when RaftCore quits
LeaderState.
-
-
Snapshot building task:
When RaftCore receives a RaftMsg that requires a snapshot, which is sent by a replication task, RaftCore spawns a sub task to build a snapshot.
Lifecycle:
- It is spawned when a snapshot is requested, and is dropped at once when the snapshot is ready.
-
User application runs in another task that spawns RaftCore task.
Communication between tasks
All tasks communicate with channels:
User
|
| write;
| change_membership;
| ...
|
| new log to
| replicate;
`---------> RaftCore -------------+-> Replication -.
^ ^ | |
| | `-> Replication -+
| | |
| `-----------------------------------'
| update replication state;
| need snapshot;
|
|
| snapshot is ready;
|
Build-snapshot
-
User to RaftCore:
RaftsendsRaftMsgthoughRaft.tx_apitoRaftCore, along with a channel forRaftCoreto send back response. -
RaftCore to Replication:
RaftCorestores a channel for every repliation task. The messages sent to replication task includes:- a new log id to replicate,
- and the index the leader has committed.
-
Replication to RaftCore:
-
Replication task sends the already replicated log id to RaftCore through another per-replication channel.
-
Replication task sends a
NeedSnapshotrequest through the same channel to ask RaftCore to build a snapshot if there is no log a follower/learner needs.
-
-
Build-snapshot to RaftCore: RaftCore spawn a separate task to build a snapshot asynchronously. When finished, the spawned task sends to RaftCore a message including the snapshot info.
Log Data Layout
There are 5 significant log ids reflecting raft log state:
old new
øøøøøøLLLLLLLLLLLLLLLLLLLL
+----+----+----+----+----+--->
| | | | |
| | | | '--- last_log_id
| | | '-------- committed
| | '------------- applied
| '------------------ snapshot_last_log_id
'----------------------- last_purged_log_id
These log ids follow a strict order:
last_purged_log_id ≤ snapshot_last_log_id ≤ applied ≤ committed ≤ last_log_id
-
last_log_id: is the last known log entry. -
committed: the last log entry that is committed, i.e., accepted and persisted by a quorum of voters, and will always be seen by all future leaders. -
applied: the committed log entry that is applied to the state-machine. In raft only committed log entry can be applied. -
snapshot_last_log_id: the greatest log id that is included in the snapshot. Openraft takes a snapshot of the state-machine periodically. Therefore, a snapshot is a compacted format of a continuous range of log entries. -
last_purged_log_id: the id of the last purged log entries. Log entries that are included in a snapshot will be purged. openraft purges logs from the start up to a configured position, when a fresh snapshot is built,last_purged_log_idis the greatest id that openraft does not store.
Vote
#![allow(unused)] fn main() { struct Vote<NID: NodeId> { leader_id: LeaderId<NID> committed: bool } // Advanced mode(default): #[cfg(not(feature = "single-term-leader"))] pub struct LeaderId<NID: NodeId> { pub term: u64, pub node_id: NID, } // Standard raft mode: #[cfg(feature = "single-term-leader")] pub struct LeaderId<NID: NodeId> { pub term: u64, pub voted_for: Option<NID>, } }
vote in openraft defines the pseudo time(in other word, defines every leader) in a distributed consensus.
Each vote can be thought as unique time point(in paxos the pseudo time is round-number or rnd, or ballot-number).
In a standard raft, the corresponding concept is term.
Although in standard raft a single term is not enough to define a time
point.
In openraft, RPC validity checking(such as when handling vote request, or
append-entries request) is very simple: A node grants a Vote which is greater than its last seen Vote:
#![allow(unused)] fn main() { fn handle_vote(vote: Vote) { if !(vote >= self.vote) { return Err(()) } save_vote(vote); Ok(()) } }
Every server state(leader, candidate, follower or learner) has a unique
corresponding vote, thus vote can be used to identify different server
states, i.e, if the vote changes, the server state must have changed.
Note: follower and learner in openraft is almost the same. The only difference is a learner does not try to elect itself.
Note: a follower will switch to a learner and vice versa without changing the vote, when a
new membership log is replicated to a follower or learner.
E.g.:
-
A vote
(term=1, node_id=2, committed=false)is in a candidate state for node-2. -
A vote
(term=1, node_id=2, committed=true)is in a leader state for node-2. -
A vote
(term=1, node_id=2, committed=false|true)is in a follower/learner state for node-3. -
A vote
(term=1, node_id=1, committed=false|true)is in another different follower/learner state for node-3.
Partial order
Vote in openraft is partially ordered value,
i.e., it is legal that !(vote_a => vote_b) && !(vote_a <= vote_b).
Because Vote.leader_id may be a partial order value:
LeaderId: advanced mode and standard mode
Openraft provides two LeaderId type, which can be switched with feature
single-term-leader:
-
cargo buildwithoutsingle-term-leader, is the advanced mode, the default mode: It builds openraft withLeaderId:(term, node_id), which is totally ordered. Which means, in a singleterm, there could be more than one leaders elected(although only the last is valid and can commit logs).-
Pros: election conflict is minimized,
-
Cons:
LogIdbecomes larger: every log has to store an additionalNodeIdinLogId:LogId: {{term, NodeId}, index}. If an application uses a bigNodeIdtype, e.g., UUID, the penalty may not be negligible.
-
-
cargo build --features "single-term-leader"builds openraft in standard raft mode with:LeaderId:(term, voted_for:Option<NodeId>), which makesLeaderIdandVotepartially-ordered values. In this mode, only one leader can be elected in eachterm.The partial order relation of
LeaderId:LeaderId(3, None) > LeaderId(2, None): true LeaderId(3, None) > LeaderId(2, Some(y)): true LeaderId(3, None) == LeaderId(3, None): true LeaderId(3, Some(x)) > LeaderId(2, Some(y)): true LeaderId(3, Some(x)) > LeaderId(3, None): true LeaderId(3, Some(x)) == LeaderId(3, Some(x)): true LeaderId(3, Some(x)) > LeaderId(3, Some(y)): falseThe partial order between
Voteis defined as: Given twoVoteaandb:a > biff:#![allow(unused)] fn main() { a.leader_id > b.leader_id || ( !(a.leader_id < b.leader_id) && a.committed > b.committed ) }In other words, if
a.leader_idandb.leader_idis not comparable(!(a.leader_id>=b.leader_id) && !(a.leader_id<=b.leader_id)), use fieldcommittedto determine the order betweenaandb.Because a leader must be granted by a quorum before committing any log, two incomparable
leader_idcan not both be granted. So let a committedVoteoverride a incomparable non-committed is safe.-
Pros:
LogIdjust store aterm. -
Cons: election conflicting rate may increase.
-
Replication
Appending entry is the only RPC to replicate logs from leader to followers or learners. Installing a snapshot can be seen as a special form of appending logs.
Append-entry
Raft logs can be together seen as a single value: An append-entry RPC forwards all logs to a follower and replace all the logs on the follower. This way it guarantees committed log can always been seen by next leader.
Although in practice, it is infeasible sending all the logs in one RPC. Thus, the receiving end in the algorithm becomes:
- Proceed only when
prev_log_idmatches local log id at the sameindex. - Save every log entry into local store if:
- the entry at the target index is empty.
- the entry at the target index is the same as the input one. Otherwise, there is an inconsistent entry, the follower must delete all entries since this one before storing the input one.
Why need to delete
The following diagram shows only log term.
R1 5
R2 5
R3 5 3 3
R4
R5 2 4 4
If log 5 is committed by R1, and log 3 is not removed, R5 in future could become a new leader and overrides log 5 on R3.
Caveat: deleting all entries after prev_log_id will get committed log lost
One of the mistakes is to delete all entries after prev_log_id when a matching prev_log_id is found, e.g.:
fn handle_append_entries(req) {
if store.has(req.prev_log_id) {
store.delete_logs(req.prev_log_id.index..)
store.append_logs(req.entries)
}
}
This results in loss of committed entry, because deleting and appending are not atomically executed.
E.g., the log entries are as following and R1 now is the leader:
R1 1,1 1,2 1,3
R2 1,1 1,2
R3
When the following steps take place, committed entry {1,2} is lost:
- R1 to R2:
append_entries(entries=[{1,2}, {1,3}], prev_log_id={1,1}) - R2 deletes
{1,2} - R2 crash
- R2 elected as leader and only see
{1,1}; the committed entry{1,2}is lost.
The safe way is to skip every entry that present in append-entries message then delete only the inconsistent entries.
Caveat: commit-index must not advance the last known consistent log
Because we can not just delete log[prev_log_id.index..], (which results in loss of committed
entry), the commit index must be updated only after append-entries
and must point to a log entry that is consistent to the leader.
Or there would be chance applying an uncommitted entry on a follower:
R0 1,1 1,2 3,3
R1 1,1 1,2 2,3
R2 1,1 1,2 3,3
- R0 to R1 append_entries:
entries=[{1,2}], prev_log_id = {1,1}, commit_index = 3 - R1 accepted this append-entries request but was not aware of that entry
{2,3}is inconsistent to leader. Then it will updatecommit_indexto3and apply{2,3}
Snapshot replication
Snapshot replication can be considered as a special form of log replication: It replicates all committed logs since the index-0 upto some index.
Similar to append-entry:
-
(1) If the logs contained in the snapshot matches logs that are stored on a Follower/Learner, nothing is done.
-
(2) If the logs conflicts with the local logs, ALL non-committed logs will be deleted, because we do not know which logs conflict. And effective membership has to be reverted to some previous non-conflicting one.
Delete conflicting logs
If snapshot_meta.last_log_id conflicts with the local log,
Because the node that has conflicting logs won't become a leader:
If this node can become a leader, according to raft spec, it has to contain all committed logs.
But the log entry at last_applied.index is not committed, thus it can never become a leader.
But, it could become a leader when more logs are received.
At this time, the logs after snapshot_meta.last_log_id will all be cleaned.
The logs before or equal snapshot_meta.last_log_id will not be cleaned.
Then there is chance this node becomes leader and uses these log for replication.
Delete all non-committed
It just truncates ALL non-committed logs here,
because snapshot_meta.last_log_id is committed, if the local log id conflicts
with snapshot_meta.last_log_id, there must be a quorum that contains snapshot_meta.last_log_id.
Thus, it is safe to remove all logs on this node.
But removing committed logs leads to some trouble with membership management.
Thus, we just remove logs since committed+1.
Not safe to clean conflicting logs after installing snapshot
It's not safe to remove the conflicting logs that are less than snap_last_log_id after installing
snapshot.
If the node crashes, dirty logs may remain there. These logs may be forwarded to other nodes if this nodes becomes a leader.
Delete conflicting logs
- When appending logs to a follower/learner, conflicting logs has be removed.
- When installing snapshot(another form of appending logs), conflicting logs should be removed.
Why
1. Keep it clean
The first reason is to keep logs clean: to keep log ids all in ascending order.
2. Committed has to be chosen
The second reason is to let the next leader always choose committed logs.
If a leader commits logs that already are replicated to a quorum,
the next leader has to have these log.
The conflicting logs on a follower A may have smaller log id than the last log id on the leader.
Thus, the next leader may choose another node B that has higher log than node A but has smaller log than the previous leader.
3. Snapshot replication does not have to delete conflicting logs
See: Deleting-conflicting-logs-when-installing-snapshot
Deleting conflicting logs when installing snapshot is only for clarity.
Extended membership change algo
Openraft tries to commit one or more membership logs to finally change the
membership to node_list.
In every step, the log it tries to commit is:
-
the
node_listitself, if it is safe to change from the previous membership tonode_listdirectly. -
otherwise, a joint of the specified
node_listand one config in the previous membership.
This algo that openraft uses is the so-called Extended membership change.
It is a more generalized form of membership change. The original 2-step joint algo and 1-step algo in raft-paper are all specialized versions of this algo.
This algo provides more flexible membership change than the original joint algo:
-
The original Joint algo:
The original joint algo in raft-paper allows changing membership in an alternate pattern of joint membership and uniform membership. E.g., the membership entry in a log history could be:
c1→c1c2→c2→c2c3→c3...Where:
cᵢis a uniform membership, such as{a, b, c};cᵢcⱼis a joint of two node lists, such as[{a, b, c}, {x, y, z}].
-
Extended algo:
Extended membership change algo allows changing membership in the following way:
c1→c1c2c3→c3c4→c4.Or revert to a previous membership:
c1c2c3→c1.
Flexibility
Another example shows that it is always safe to change membership from one to another along the edges in the following diagram:
c3
/ \
/ \
/ \
c1c3 ------ c2c3
/ \ / \
/ \ / \
/ \ / \
c1 ----- c1c2 ----- c2
Disjoint memberships
A counter-intuitive conclusion is that:
Even when two leaders propose two memberships without intersection, consensus will still, be achieved.
E.g., given the current membership to be c1c2, if
L1 proposed c1c3,
L2 proposed c2c4.
There won't be a brain split problem.
Spec of extended membership change algo
This algo requires four constraints to work correctly:
-
(0) use-at-once: The new membership that is appended to log will take effect at once, i.e., openraft uses the last seen membership config in the log, no matter it is committed or not.
-
(1) propose-after-commit: A leader is allowed to propose new membership only when the previous one is committed.
-
(2) old-new-intersect(safe transition): (This is the only constraint that is loosened from the original raft) Any quorum in new membership(
m') intersect with any quorum in the old committed membership(m):∀qᵢ ∈ m, ∀qⱼ ∈ m':qᵢ ∩ qⱼ ≠ ø. -
(3) initial-log: A leader has to replicate an initial blank log to a quorum in last seen membership to commit all previous logs.
In our implementation, (2) old-new-intersect is simplified to: The new membership has to contain a config entry that is the same as one in the last committed membership.
E.g., given the last committed one is [{a, b, c}], then a valid new membership may be:
a joint membership: [{a, b, c}, {x, y, z}].
If the last committed one is [{a, b, c}, {x, y, z}], a valid new membership
may be: [{a, b, c}], or [{x, y, z}].
Proof of correctness
Assumes there was a brain split problem occurred,
then there are two leaders(L1 and L2) proposing different membership(m1 and m2(mᵢ = cᵢcⱼ...)):
L1: m1,
L2: m2
Thus the L1 log history and the L2 log history diverged.
Let m0 be the last common membership in the log histories:
L1 L2
m1 m2
\ /
\ o term-2
\ |
`--o term-1
|
m0
From (1) propose-after-commit,
L1must have committed log entrym0to a quorum inm0interm_1.L2must have committed log entrym0to a quorum inm0, interm_2.
Assumes term_1 < term_2.
From (3) initial-log, L2 has at least one log with term_2 committed in a
quorum in m0.
∵ (2) old-new-intersect and term_1 < term_2
∴ log entry m1 can never be committed by L1,
because log replication or voting will always see a higher term_2 on a node in a quorum in m0.
For the same reason, a candidate with log entry m1 can never become a leader.
∴ It is impossible that there are two leaders that both can commit a log entry.
QED.
Effective membership
In openraft a membership config log takes effect as soon as it is seen.
Thus, the effective membership is always the last present one found in log.
The effective membership is volatile before being committed: because non-committed logs has chance being overridden by a new leader. Thus, the effective membership needs to be reverted to the previous one, i.e., the second last membership config log entry along with the conflicting logs being deleted.
Because Raft does not allow to propose new membership config if the effective one has not yet committed, The Raft Engine only need to keep track of at most two membership configs: the last committed one and the effective one.
The second last membership log has to be committed.
#![allow(unused)] fn main() { pub struct MembershipState<NID: NodeId> { pub committed: Arc<EffectiveMembership<NID>>, pub effective: Arc<EffectiveMembership<NID>>, } }
When deleting conflicting logs that contain a membership config log on a Follower/Learner, it needs to revert at most one membership config to previous one, i.e., discard the effective one and make the last committed one effective.
Upgrade tips
First, have a look at the change log for the version to upgrade to. A commit message starting with these keywords needs attention:
-
Change: introduces breaking changes. Your application needs adjustment to pass compilation. If storage related data structure changed too, a data migration tool is required for the upgrade. See below.
-
Feature: introduces non-breaking new features. Your application should compile without modification.
-
Fix: bug fix. No modification is required.
Upgrade from v0.6.8 to v0.7.0:
Guide for upgrading v0.6 to v0.7
Upgrade from v0.6.5 to v0.6.6:
just modify application code to pass compile.
- API changes: struct fields changed in
StorageIOErrorandViolation. - Data changes: none.
Guide for upgrading from v0.6.* to v0.7.*:
In this chapter, for users who will upgrade openraft 0.6 to openraft 0.7, we are going to explain what changes has been made from openraft-0.6 to openraft-0.7 and why these changes are made.
-
A correct upgrading should compile and at least passes the Storage test, as
memstoredoes. -
Backup your data before deploying upgraded application.
To upgrade:
-
Update the application to adopt
v0.7.*openraft.memstoreis a good example about how to implement the openraft API. Also, the new implementation ofv0.7.*has to passRaftStoragetest suite. -
Then shutdown all
v0.6.*nodes and then bring upv0.7.*nodes.
v0.6.* and v0.7.* should NEVER run in a same cluster, due to the data structure changes.
Exchanging data between v0.6.* and v0.7.* nodes may lead to data damage.
Storage API changes
RaftStorage:
-
The following APIs are removed from
RaftStorage:RaftStorage::get_membership_config() RaftStorage::get_initial_state() RaftStorage::get_log_entries() RaftStorage::try_get_log_entry()When migrating from 0.6 to 0.7, just remove implementations for these method. These methods are provided by a
StorageHelperin 0.7 .Why:
These tasks are almost the same in every openraft application. They should not bother application author to implement them.
-
Merged the following log state methods in openraft-0.6 into one method
RaftStorage::get_log_state():RaftStorage::first_id_in_log() RaftStorage::first_known_log_id() RaftStorage::last_id_in_log()The new and only log state API signature in 0.7 is:
RaftStorage::get_log_state() -> Result<LogState, _>.When migrating from 0.6 to 0.7, replace these three methods with
get_log_state().get_log_state()should returns the last purged log id and the last known log id. An application using openraft-0.7 should store the last-purged log id in its store, whenRaftStorage::purge_logs_upto()is called.Why:
Reading log state should be atomic, such a task should be done with one method.
-
Split
RaftStorage::delete_logs_from(since_log_index..upto_log_index)into two methods:-
RaftStorage::purge_logs_upto(log_id)Delete applied logs from the beginning to the specified log id and store thelog_idin the store. -
RaftStorage::delete_conflict_logs_since(log_id)Delete logs that conflict with the leader on a follower, since the specifiedlog_idto the last log.
Why:
These two deleting logs tasks are slightly different:
- Purging applied logs does not have to be done at once, it can be delayed by an application for performance concern.
- Deleting conflicting logs has to be done before returning.
And openraft does not allows a hole in logs, splitting
deleteoperation into these two methods prevents punching a hole in logs, which is potentially a bug. -
-
The return value of
RaftStorage::last_applied_state()is changed to(Option<LogId>, _), since mostLogIdin openraft code base are replaced withOption<LogId>. -
Rename:
RaftStorage::do_log_compaction() => build_snapshot() RaftStorage::finalize_snapshot_installation() => install_snapshot()There is no function changes with these two methods.
Data type changes
-
Replace several field type
LogIdwithOption<LogId>.Storage related fields that are changed:
InitialState.last_log_id InitialState.last_applied SnapshotMeta.last_log_idRPC related fields that are changed:
VoteRequest.last_log_id VoteResponse.last_log_id AppendEntriesRequest.prev_log_id AppendEntriesRequest.leader_commit AppendEntriesResponse.conflict AddLearnerResponse.matched StateMachineChanges.last_appliedWhen migrating from 0.6 to 0.7, wrap these field with a
Some().Why:
Explicitly describe uninitialized state by giving uninitialized state a different type variant. E.g., Using
0as uninitialized log index, there is chance mistakenly using0to write to or read from the storage. -
For the similar reason, replace
EffectiveMembershipwithOption<EffectiveMembership>. -
New struct
LogState:(LogState.last_purge_log_id, LogState.last_log_id]is the range of all present logs in storage(left-open, right-close range).This struct type is introduced along with
RaftStorage::get_log_state(). -
RPC:
AppendEntriesResponse: removed fieldmatched: because if it is a successful response, the leader knows what the last matched log id.Add a new field
successand changeconflictto a simplebool, because if there is a log that conflicts with the leader's, it has to be theprev_log_id. -
ClientWriteRequest: removed it is barely a wrapper of EntryPayload client_write
Guide for upgrading from v0.7.* to v0.8.3:
In this chapter, for users who will upgrade openraft 0.7 to openraft 0.8, we are going to explain what changes has been made from openraft-0.7 to openraft-0.8 and why these changes are made.
- Backup your data before deploying upgraded application.
To upgrade:
-
Update the application to adopt
v0.8.3openraft. The updatedRaftStorageimplementation must passRaftStoragetest suite, and the compatibility test: compatibility test -
Then shutdown all
v0.7.*nodes and then bring upv0.8.*nodes.
v0.7.* and v0.8.* should NEVER run in a same cluster, due to the data structure changes.
Exchanging data between v0.7.* and v0.8.* nodes may lead to data damage.
Upgrade steps
In general, the upgrade includes the following steps:
Prepare v0.8
-
Make sure that the application uses
serdeto serialize data; Openraft v0.8 provides a compatibility layer that is built uponserde. -
Enable feature flag
compat-07to enable the compatibility layeropenraft::compat::compat07. -
Optionally enable feature flag
single-term-leaderif the application wants to use standard raft. See Multi/single leader in each term chapter.
Upgrade the application codes
-
Add type config to define what types to use for openraft, See RaftTypeConfig :
#![allow(unused)] fn main() { openraft::declare_raft_types!( pub MyTypeConfig: D = ClientRequest, R = ClientResponse, NodeId = u64, Node = openraft::EmptyNode, Entry = openraft::entry::Entry<MyTypeConfig> ); } -
Add generics parameter to types such as:
LogId -> LogId<NID>,Membership -> Membership<NID, N>Entry<D> -> Entry<MyTypeConfig>
-
Move
RaftStoragemethods implementation according to the Storage API changes chapter.- Replace
HardStatewithVote, and[read/save]_hard_statewith[read/write]_vote. - Replace
EffectiveMembershipwithStoredMembership.
- Replace
-
Move
RaftNetworkmethods implementation according to the Network-API-changes chapter. -
Replace types for deserialization with the ones provided by
openraft::compat::compat07. These types such ascompat07::Entrycan be deserialized from both v0.7Entryand v0.8Entry. -
Finally, make sure the
RaftStorageimplementation passesRaftStoragetest suite and compatibility test
Compatibility with v0.7 format data
Openraft v0.8 can be built compatible with v0.7 if:
- The application uses
serdeto serialize data types - Enabling
compat-07feature flags.
Openraft uses a RaftStorage implementation provided by the application to
store persistent data. When upgrading from v0.7 to v0.8, it is important to
ensure that the updated RaftStorage is backward compatible and can read the
data written by v0.7 openraft, in addition to reading and writing v0.8 openraft data.
This ensures that the application continues to function smoothly after upgrade.
Openraft v0.8 compatible mode
Compared to v0.7, openraft v0.8 has a more generic design.
However, it is still possible to build it in a v0.7 compatible mode by enabling
the feature flag compat-07.
More information can be found at: feature-flag-compat-07.
It is worth noting that an application does NOT need to enable this feature flag if it chooses to manually upgrade the v0.7 format data.
Generic design in v0.8 includes:
- generic type
NodeId,NodeandEntrywere introduced, serdebecame an optional.
Because of these generalizations, feature compat-07 enables the following feature flags:
serde: it addsserdeimplementation to types such asLogId.
And v0.8 will be compatible with v0.7 only when it uses u64 as NodeId and openraft::EmptyNode as Node.
Implement a compatible storage layer
In addition to enabling compat-07 feature flag, openraft provides a compatible layer in
openraft::compat::compat07 to help application developer to upgrade.
This mod provides several types that can deserialize from both v0.7 format data and the latest format data.
An application uses these types to replace the corresponding ones in a
RaftStorage implementation, so that v0.7 data and v0.8 data can both be read.
For example, in a compatible storage implementation, reading a LogId should be
done in the following way:
#![allow(unused)] fn main() { use openraft::compat::compat07; fn read_log_id(bs: &[u8]) -> openraft::LogId<u64> { let log_id: compat07::LogId = serde_json::from_slice(&bs).expect("incompatible"); let latest: openraft::LogId<u64> = log_id.upgrade(); latest } }
Example of compatible storage
rocksstore-compat07
is a good example using these compatible type to implement a compatible RaftStorage.
This is an example RaftStorage implementation that can read persistent
data written by either v0.7.4 or v0.8 the latest version openraft.
rocksstore-compat07 is built with openraft 0.8, in the tests, it reads data written by rocksstore 0.7.4, which is built with openraft 0.7.4 .
In this example, it loads data through the compatibility layer:
openraft::compat::compat07, which defines several compatible types
that can be deserialized from v0.7 or v0.8 data, such as
compat07::LogId or compat07::Membership.
Test compatibility
Openraft also provides a testing suite testing::Suite07 to ensure old data will be correctly read.
An application should ensure that its storage passes this test suite.
Just like rocksstore-compat07/compatibility_test.rs does.
To test compatibility of the application storage API:
- Define a builder that builds a v0.7
RaftStorageimplementation. - Define another builder that builds a v0.8
RaftStorageimplementation. - Run tests in
compat::testing::Suite07with these two builder. In this test suite, it writes data with a v0.7 storage API and then reads them with an v0.8 storage API.
#![allow(unused)] fn main() { use openraft::compat; struct Builder07; struct BuilderLatest; #[async_trait::async_trait] impl compat::testing::StoreBuilder07 for Builder07 { type D = rocksstore07::RocksRequest; type R = rocksstore07::RocksResponse; type S = Arc<rocksstore07::RocksStore>; async fn build(&self, p: &Path) -> Arc<rocksstore07::RocksStore> { rocksstore07::RocksStore::new(p).await } fn sample_app_data(&self) -> Self::D { rocksstore07::RocksRequest::Set { key: s("foo"), value: s("bar") } } } #[async_trait::async_trait] impl compat::testing::StoreBuilder for BuilderLatest { type C = crate::Config; type S = Arc<crate::RocksStore>; async fn build(&self, p: &Path) -> Arc<crate::RocksStore> { crate::RocksStore::new(p).await } fn sample_app_data(&self) -> <<Self as compat::testing::StoreBuilder>::C as openraft::RaftTypeConfig>::D { crate::RocksRequest::Set { key: s("foo"), value: s("bar") } } } #[tokio::test] async fn test_compatibility_with_rocksstore_07() -> anyhow::Result<()> { compat::testing::Suite07 { builder07: Builder07, builder_latest: BuilderLatest, }.test_all().await?; Ok(()) } fn s(v: impl ToString) -> String { v.to_string() } }
Summary of changes introduced in v0.8
Generic Node
Openraft v0.8 introduces trait openraft::NodeId, openraft::Node, openraft::entry::RaftEntry, an application now
can use any type for a node-id or node object.
A type that needs NodeId or Node now has generic type parameter in them,
e.g, struct Membership {...} became:
#![allow(unused)] fn main() { pub struct Membership<NID, N> where N: Node, NID: NodeId {...} }
Optional serde
serde in openraft v0.8 became optional. To enable serde, build openraft with
serde feature flag. See: feature flags.
Multi/single leader in each term
Openraft v0.8 by default allows multiple leaders to be elected in a single term, in order to minimize conflicting during election.
To run in the standard raft mode, i.e, only one leader can be elected in every
term, an application builds openraft with feature flag "single-term-leader".
See: feature flags.
With this feature on: only one leader can be elected in each term, but
it reduces LogId size from LogId:{term, node_id, index} to LogId{term, index}.
It will be preferred if an application uses a big NodeId type.
Openraft v0.7 runs in the standard raft mode, i.e., at most one leader per term. It is safe to upgrade v0.7 single-term-leader mode to v0.8 multi-term-leader mode.
Storage API changes
Split RaftStorage
Extract RaftLogReader, RaftSnapshotBuilder from RaftStorage
RaftStorage is now refactored to:
RaftLogReaderto read data from the log in parallel tasks independent of the main Raft loopRaftStorageto modify the log and the state machine (implements alsoRaftLogReader) intended to be used in the main Raft loopRaftSnapshotBuilderto build the snapshot in background independent of the main Raft loop
The RaftStorage API offers to create new RaftLogReader or RaftSnapshotBuilder on it.
Move default implemented methods from RaftStorage to StorageHelper
Function get_log_entries() and try_get_log_entry() are provided with default implementations. However, they do not need to be part of this trait and an application does not have to implement them.
Network API changes
Split RaftNetwork and RaftNetworkFactory
RaftNetwork is also refactored to:
RaftNetworkresponsible for sending RPCsRaftNetworkFactoryresponsible for creating instances ofRaftNetworkfor sending data to a particular node.
Data type changes
-
When building a
SnapshotMeta, another field is required:last_membership, for storing the last applied membership. -
HardStateis replaced withVote. -
Add
SnapshotSignatureto identify a snapshot for transport. -
Replace usages of
EffectiveMembershipinRaftStoragewithStoredMembership. -
Introduce generalized types
NodeIdandNodeto let user defines arbitrary node-id or node. Openraft v0.8 relies on aRaftTypeConfigfor your application to define types that are used by openraft, with the following macro:#![allow(unused)] fn main() { openraft::declare_raft_types!( pub MyTypeConfig: D = ClientRequest, R = ClientResponse, NodeId = u64, Node = openraft::EmptyNode, Entry = openraft::entry::Entry<MyTypeConfig> ); }
Obsolete Designs
Several designs in Openraft have been discarded due to the problems they caused for applications. These designs were attempts at optimization or simplification, but ultimately proved to be inappropriate. They are included in this chapter as an archive to explain why they were discarded.
Obsolete: blank log heartbeat
https://github.com/datafuselabs/openraft/issues/698
This design has two problems:
-
The heartbeat that sends a blank log introduces additional I/O, as a follower has to persist every log to maintain correctness.
-
Although
(term, log_index)serves as a pseudo time in Raft, measuring whether a node has caught up with the leader and is capable of becoming a new leader, leadership is not solely determined by this pseudo time. Wall clock time is also taken into account.There may be a case where the pseudo time is not upto date but the clock time is, and the node should not become the leader. For example, in a cluster of three nodes, if the leader (node-1) is busy sending a snapshot to node-2(it has not yet replicated the latest logs to a quorum, but node-2 received message from the leader(node-1), thus it knew there is an active leader), node-3 should not seize leadership from node-1. This is why there needs to be two types of time, pseudo time
(term, log_index)and wall clock time, to protect leadership.In the follow graph:
- node-1 is the leader, has 4 log entries, and is sending a snapshot to node-2,
- node-2 received several chunks of snapshot, and it perceived an active leader thus extended leader lease.
- node-3 tried to send vote request to node-2, although node-2 do not have as many logs as node-3, it should still reject node-3's vote request because the leader lease has not yet expired.
In the obsolete design, extending pseudo time
(term, index)with atick, in this case node-3 will seize the leadership from node-2.Ni: Node i Ei: log entry i N1 E1 E2 E3 E4 | v N2 snapshot +-----------------+ ^ | | leader lease | N3 E1 E2 E3 | vote-request ---------------+----------------------------> clock time now
The original document is presented below for reference.
Heartbeat in openraft
Heartbeat in standard raft
Heartbeat in standard raft is the way for a leader to assert it is still alive:
- A leader send heartbeat at a regular interval.
- A follower that receives a heartbeat believes there is an active leader thus it rejects election request(
send_vote) from another node unreachable to the leader, for a short period.
Openraft heartbeat is a blank log
Such a heartbeat mechanism depends on clock time. But raft as a distributed consensus already has its own pseudo time defined very well. Raft, or other consensus protocol has its own pseudo time defined internally:
- In paxos it is
round_number(AKA ballot number in some paper). - In the standard raft it is
(term, voted_for, last_log_index)(because in standard raft there is only one leader in every term,voted_forcan be removed:(term, last_log_index)).
The pseudo time in openraft is a tuple (vote, last_log_id), compared in dictionary order(vote is equivalent concept as round number in Paxos).
Why it works
To refuse the election by a node that does not receive recent messages from the current leader, just let the active leader send a blank log to increase the pseudo time on a quorum.
Because the leader must have the greatest pseudo time, thus by comparing the pseudo time, a follower automatically refuse election request from a node unreachable to the leader.
And comparing the pseudo time is already done by handle_vote_request(),
there is no need to add another timer for the active leader.
Thus making heartbeat request a blank log is the simplest way.
Why blank log heartbeat?
-
Simple, get rid of a timer.
Without heartbeat log(the way standard raft does), when handling a vote request, except
voteitself, it has to examine two values to determine if the vote request is valid:- Whether the last heartbeat has expired by clock time.
- Whether the
(last_term, last_log_index)in the request is greater or equal to the local value. This is the pseudo time Raft defines.
With heartbeat log(the way openraft does), when handling a vote request, it only needs to examine one value: the raft time:
(last_term, last_log_index). This makes the logic simpler and the test easier to write. -
Easy to prove, and reduce code complexity.
Concerns
-
More raft logs are generated. This requires to persist the blank entry in the log (or at least the incremented index). E.g., doing that every 50ms for 100 consensus domains on one machine will require 2000 IOPS alone for that.
Why it is not a problem:
-
Assume that most consensus domains are busy, and as a domain is busy, it is possible to merge multiple
append-entrycalls into one call to the storage layer. Thus if a domain swallows10business log entries per50 ms, it's likely to merge these 10 entries into one or a few IO calls. The IO amplification should be smaller as IOPS gets more.Merging entries into one IO call is naturally done on followers(because the leader sends entries in a batch). On the leader, it's not done yet(2022 Sep 13). It can be done when the Engine oriented refactoring is ready: (.
-
If a consensus domain swallows
1business log entry per50 ms. It does not need another heartbeat. A normal append-entry can be considered a heartbeat.
-